mr 计算框架
假如有三台机器 统领者master 01 02 03 每台机器都有过滤的应用程序
移动数据 01机== 300M 》mr 移动计算 java程序传递给各个机器(mr)
伪分布式安装 一个机器上,即当namenode,又当datanode,或者说即是jobtracker,又是tasktracker。
没有所谓的在多台机器上进行真正的分布式计算,故称为"伪分布式"。(一台机器模拟多台linux机器)
Hadoop2三大核心
三大核心:HDFS文件存储、MapReduce计算框架、YARN资源管理
Hadoop四个模块
Hadoop Common: 为其他Hadoop模块提供基础设施。(工具类)
Hadoop DFS: 一个高可靠、高吞吐量的分布式文件系统
Hadoop MapReduce: 一个分布式的离线并行计算框架
Hadoop YARN: 一个新的MapReduce框架,任务调度与资源管理
HDFS的介绍
源自于Google的GFS论文 发表于2003年10月
HDFS是GFS克隆版Hadoop Distributed File System
易于扩展的分布式文件系统运行在大量普通廉价机器上,
提供容错机制 为大量用户提供性能不错的文件存取服务
提供大量冗余的机器(数据进行备份)
HDFS设计目标
1.自动快速检测应对硬件错误
pc 宕机损坏 快速检测到错误 然后又备份出来 (将坏掉的机器检测出来,然后快速的备份文件)
01.(额定数量的备份 hdfs快速检测出来)
把备份的数据进行与mr的交互
02.额定备份 还会再次进行备份
2.流式访问数据(易读不易写)
容易读但是不易追加 mysql不是流式访问数据 可以经常修改
3.移动计算比移动数据本身更划算 io
1.减少io损耗2.分布式处理 并行计算
4.简单一致性模型
5.异构平台可移植
HDFS的特点
优点:
(一)高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖;
(进行备份)
(二)高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,
这些集簇可以方便地扩展到数以千计的节点中。(单节点是1台机器多节点是多台机器)
(三)高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(四)高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
缺点:
(一)不适合低延迟数据访问。
(二)无法高效存储大量小文件。
(三)不支持多用户写入及任意修改文件。
设计假设和目标
硬件错误:数量众多的廉价机器使得硬件错误成为常态。
数据流访问:应用以流的方式访问数据;设计用于数据的批量处理,而不是低延时的实时交互处理。放弃全面支持POSIX。
大数据集:典型的HDFS上的一个文件大小是G或T数量级的,支持一个云中文件数量达到千万数量级。
简单的相关模型:假定文件一次写入多次读取。未来可能支持Appending-write的模型。
移动计算比移动数据便宜:一个应用请求的计算,离它操作的数据越近就越高效。 多种软硬件平台中的可移植性
HDFS三个服务
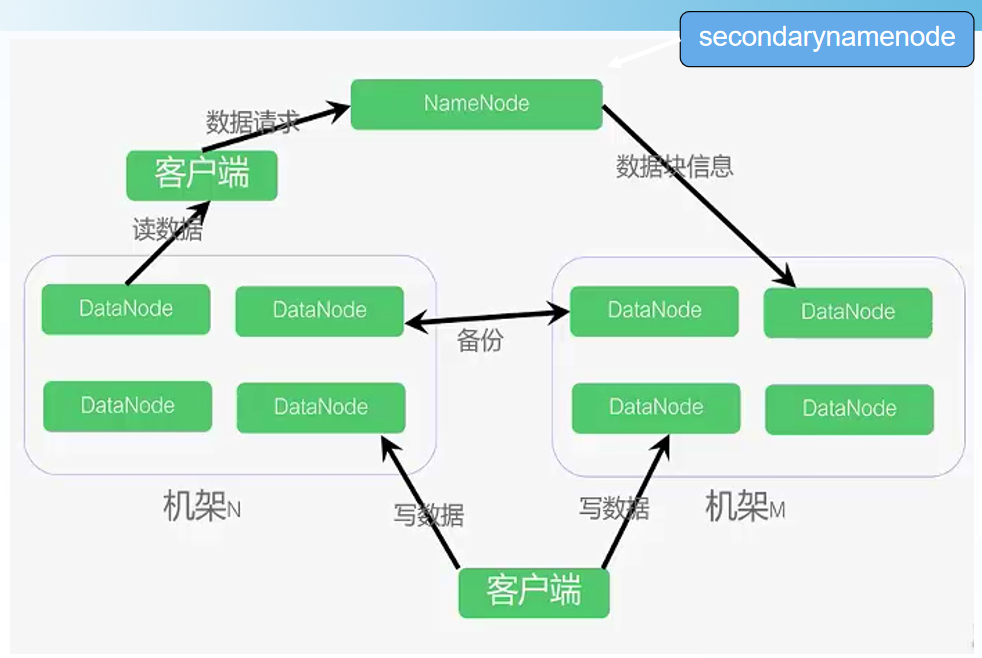
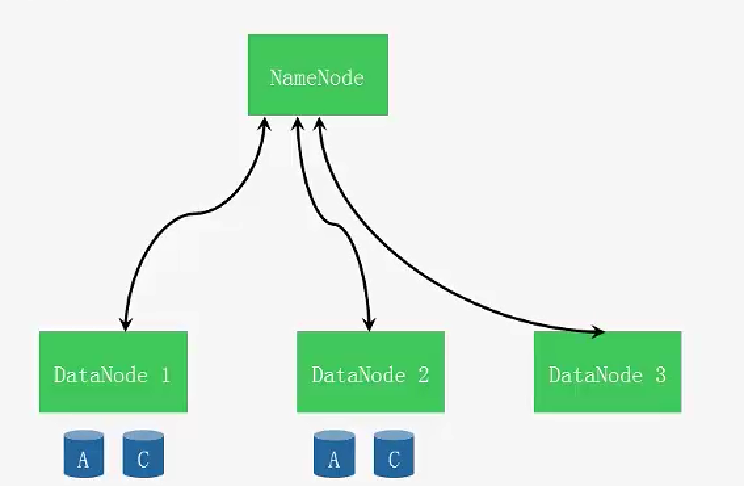
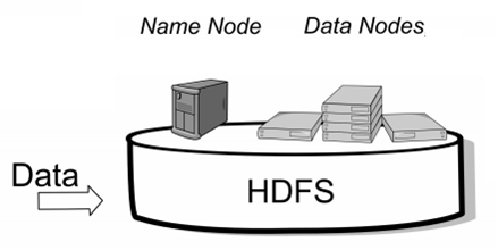
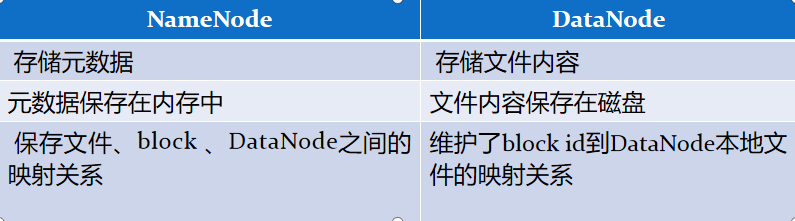
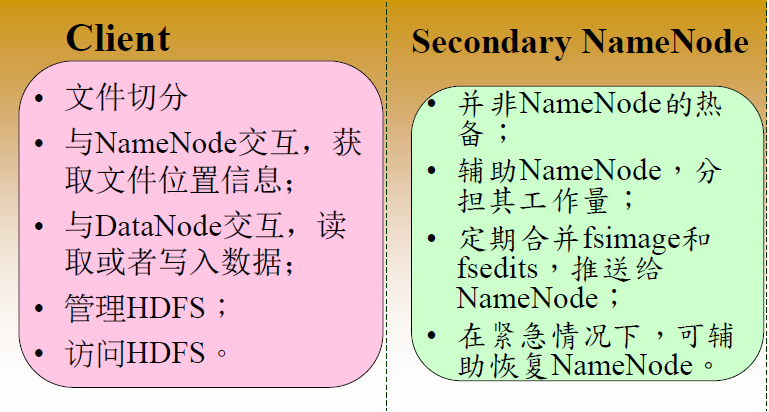
1.NameNode metadata 元数据 (统领者主机器) (nameNode记录数据怎么存储的 ==》 数据存储在DataNode里面 3)
2.Secondary NameNode 秘书
3.DataNode 数据 数据:数据内容 元数据:文件名称 大小 所属人 地址 128k
假如有三台机器 01机(99%的内存) 02机(1%)03机 (NameNode 记录block块统领DataNode 会告诉往内存的少的服务器上存)
三个服务相当于三个进程 三个进程相当于三个应用程序
分布式的系统 不止一台机器 多台机器

HDFS Architecture
基本概念 元数据:镜像文件(Fsimage)+日志文件(Edits) 用户数据
主从节点通讯
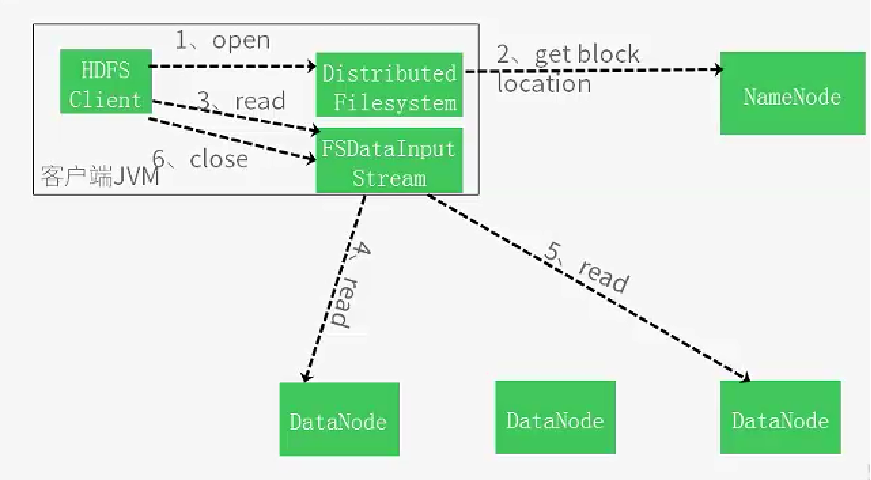
写数据流程

读数据流程
HDFS 架构 — NameNode
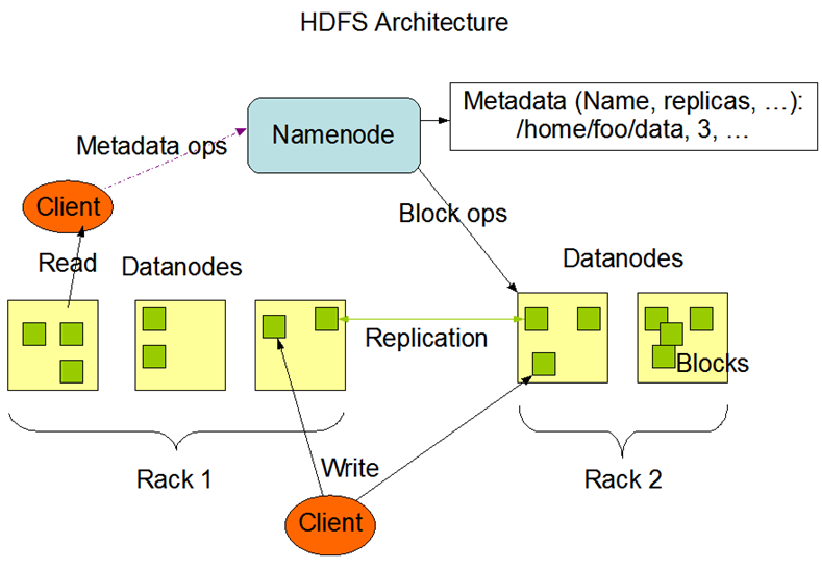
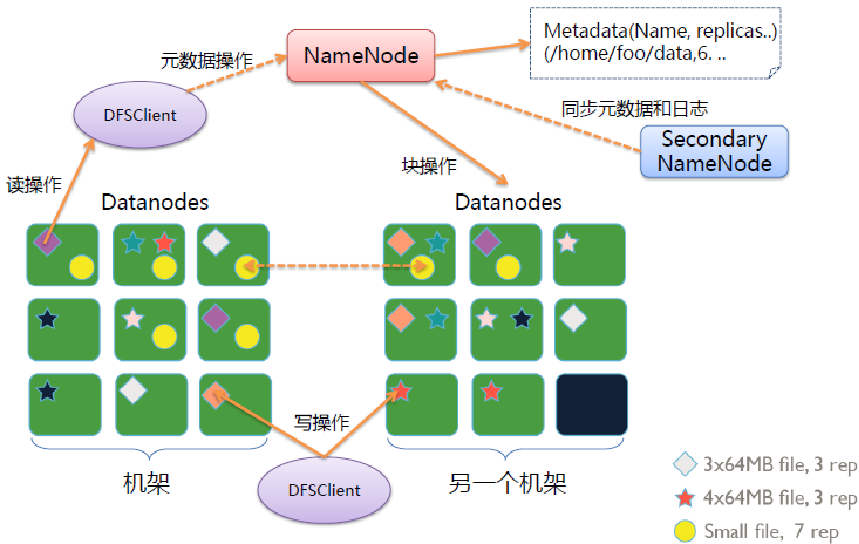
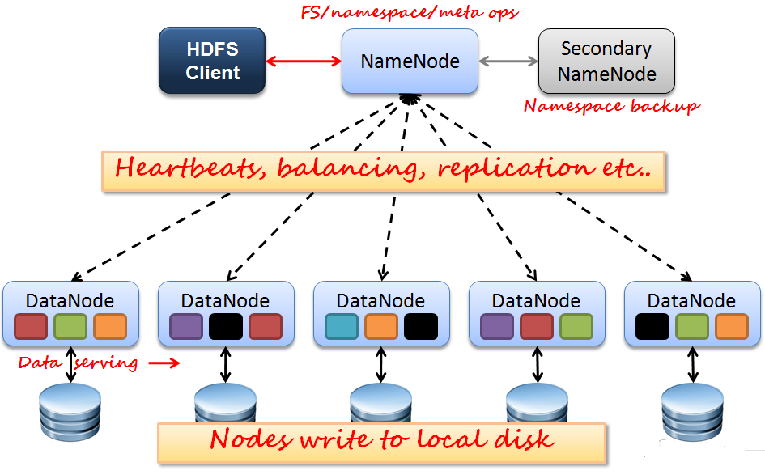
Namenode 是一个中心服务器,单一节点(简化系统的设计和实现),
负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
文件操作,NameNode 负责文件元数据的操作,DataNode负责处理文件内容的读写请求,
跟文件内容相关的数据流不经过NameNode,只会询问它跟那个DataNode联系,否则NameNode会成为系统的瓶颈。
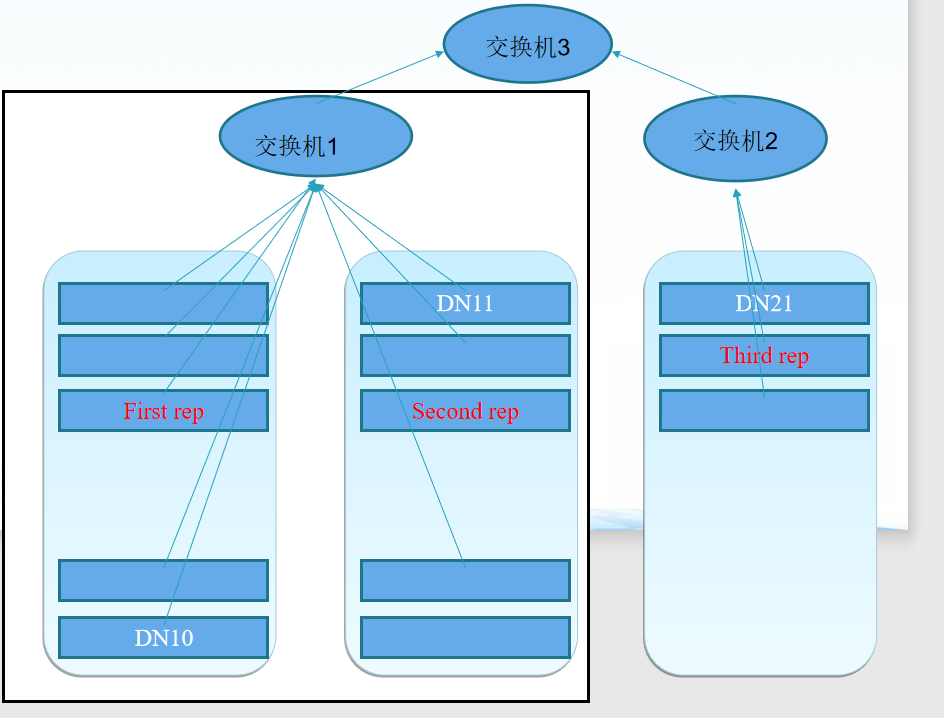
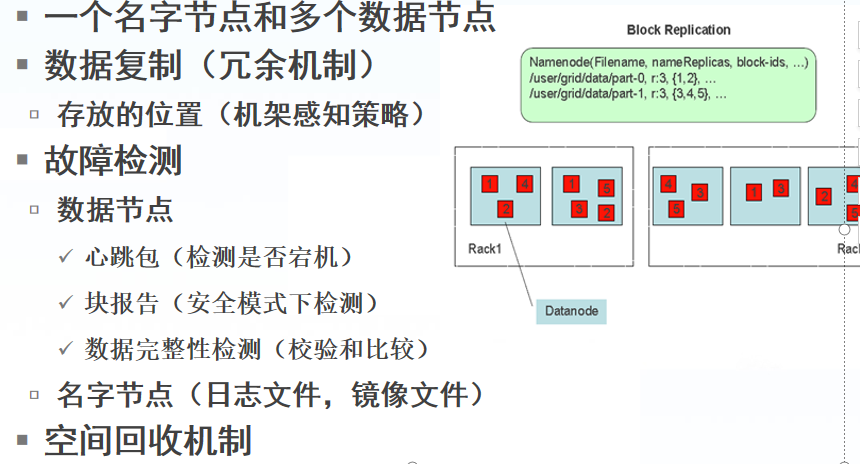
副本存放在哪些DataNode上由 NameNode来控制,根据全局情况做出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,
降低带块消耗和读取时延(机架感知)
Namenode 全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。
接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
HDFS 架构 — DataNode
一个数据块在DataNode以文件存储在磁盘上,包括两个文件,一个是数据本身,
一个是元数据包括数据块的长度,块数据的校验和,以及时间戳
DataNode启动后向NameNode注册,通过后,周期性(1周)的向NameNode上报所有的块信息。
心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,
或删除某个数据块。如果超过10分钟没有收到某个DataNode 的心跳,则认为该节点不可用。
集群运行中可以安全加入和退出一些机器
HDFS 架构 — 文件
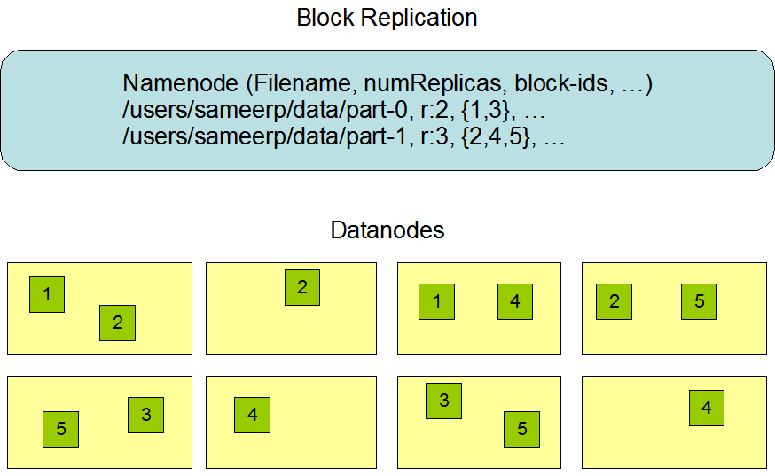
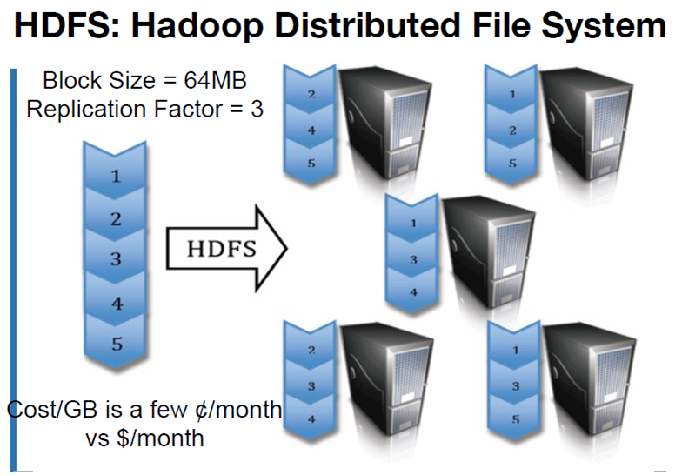
文件切分成块(默认大小128M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3)
NameNode 是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表以及块所在的DataNode等等
DataNode 在本地文件系统存储文件块数据,以及块数据的校验和。
可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容。
HDFS Architecture
HDFS 文件权限
与Linux文件权限类似。
r: read; w:write; x:execute,权限x对于文件忽略,对于文件夹表示是否允许访问其内容。
如果Linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan。
HDFS的权限目的:阻止好人做错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁。
HDFS Architecture
HDFS Architecture

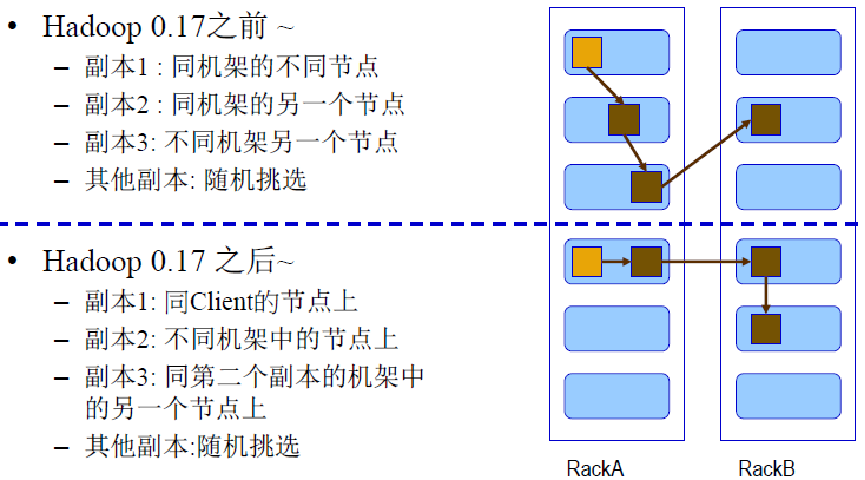
HDFS 副本放置策略
HDFS 架构 — 组件功能
HDFS 架构 —可靠性
数据损坏(corruption)处理
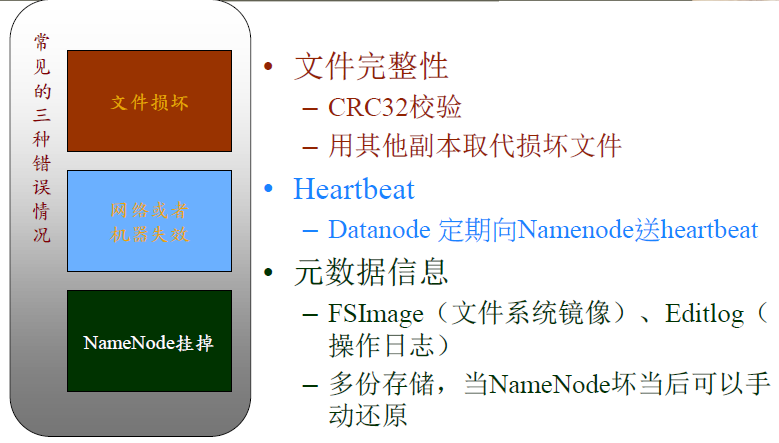
当DataNode读取block的时候,它会计算checksum
如果计算后的checksum,与block创建时值不一样,说明该block已经损坏。
Client读取其它DN上的block。
NameNode标记该块已经损坏,然后复制block达到预期设置的文件备份数
DataNode 在其文件创建后三周验证其checksum。
HDFS Architecture
NameNode 启动过程
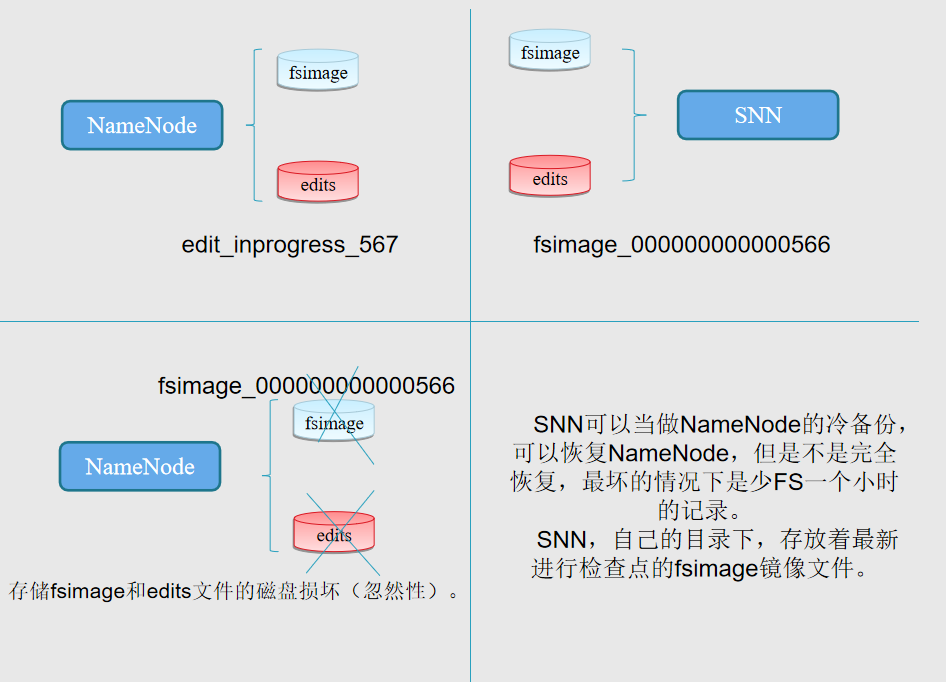
NameNode 元数据/命名空间持久化 fsimage与edits
NameNode 格式化,具体做什么事 format
创建fsimage文件,存储fsimage信息
创建edits文件
NameNode启动过程
加载fsimage和edits文件
生成新的fsimage和edits_new文件
等待DataNode注册与发送Block Report
DataNode 启动过程
向NameNode注册、发送Block Report
NameNode SafeMode 安全模式
NameNode 启动过程
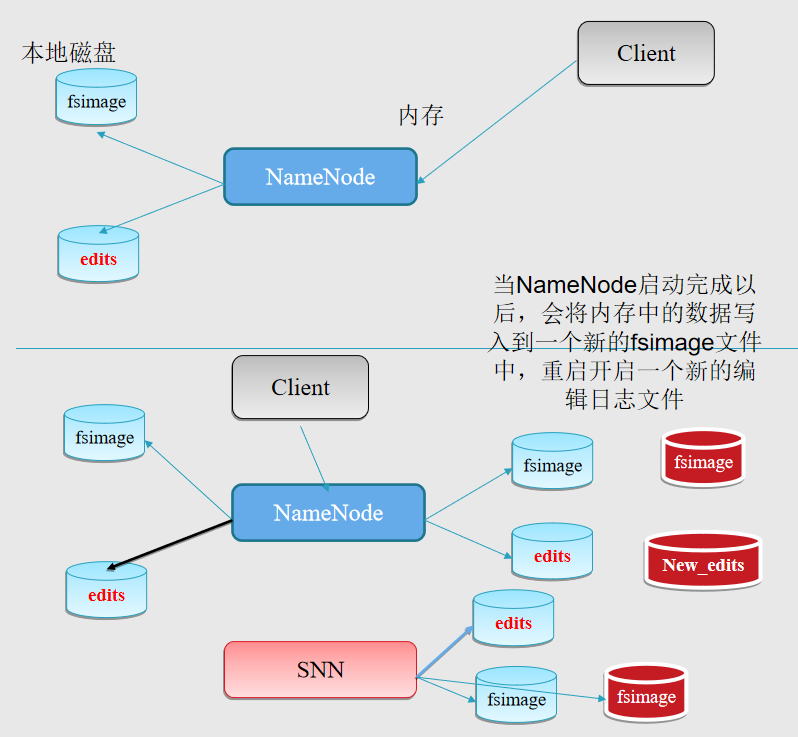
1、Name启动的时候首先将fsimage(镜像)载入内存,并执行(replay)编辑日志editlog的的各项操作;secondaryNamenode和namenode不能在一台机器中
2、一旦在内存中建立文件系统元数据映射,则创建一个新的fsimage文件(这个过程不需SecondaryNameNode) 和一个空的editlog;
3、在安全模式下,各个datanode会向namenode发送块列表的最新情况;
4、此刻namenode运行在安全模式。即NameNode的文件系统对于客户端来说是只读的。(显示目录,显示文件内容等。写、删除、重命名都会失败);
5、NameNode开始监听RPC和HTTP请求 解释RPC:RPC(Remote Procedure Call Protocol)
——远程过程通过协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议;
6、系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中;
7、在系统的正常操作期间,namenode会在内存中保留所有块信息的映射信息。
Hadoop Safe Mode
1、查询当前是否安全模式
shell> hadoop dfsadmin -safemode get
Safe mode is ON
当然也可以通过Web UI查看
2、等待safemode关闭,以便后续操作
shell> hadoop dfsadmin -safemode wait
3、退出安全模式
shell> hadoop dfsadmin -safemode leave Safe mode is
OFF 另一种方式,就是调小dfs.namenode.safemode.threshold-pct
4.设置启用safemode
shell> hadoop dfsadmin -safemode enter
Safe mode is ON
在进行一些集群维护操作时很有用,可以保持数据依然可读。也可以在集群已是安全模式使执行,确保进入安全模式。
Hadoop Safe Mode
dfs.namenode.replication.min 默认为1。
NameNode中设定所需要的数据块最低复制份数。只有大于等于这个值,
才会认为块是有效的 dfs.namenode.safemode.threshold-pct 默认值 0.999f。参数指定满足
dfs.namenode.replication.min复制份数要求的Block数量的比率,超过这个比率后NameNode才能脱离安全模式。
若小于0,则不需要等待DataNode的块报告就离开SafeMode,这会使得数据完整性无法保证;若大于1,则永远处于安全模式。
dfs.namenode.safemode.extension 默认30000,单位毫秒。
安全模式的延期时间,即到达dfs.namenode.safemode.threshold-pct设置的阈值后,会再等待这么长时间,可以认为是等待一个稳定的集群环境。
dfs.namenode.safemode.min.datanodes 默认0。
设置NameNode退出安全模式前确认活跃的DataNode数量。小于等于0表示不考虑活跃DataNode的影响,大于集群中DataNode总数则使得永远处于安全模式。
SafeMode 相关说明
安全模式下,集群属于只读状态。但是严格来说,只是保证HDFS元数据信息的访问,
而不保证文件的访问,因为文件的组成Block信息此时NameNode还不一定已经知道了。
所以只有NameNode已了解了Block信息的文件才能读到。而安全模式下任何对HDFS有更新的操作都会失败。
对于全新创建的HDFS集群,NameNode启动后不会进入安全模式,因为没有Block信息。
HDFS 架构 — Client & SNN

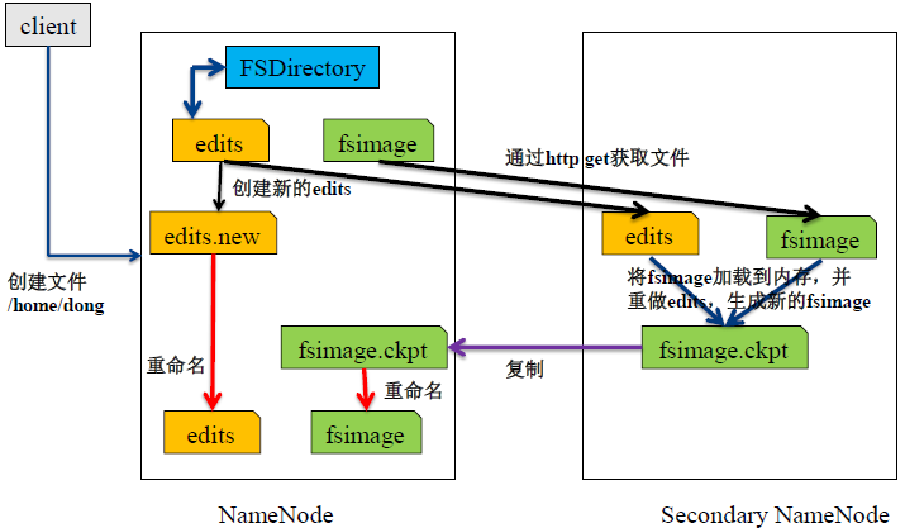
HDFS 架构 — Client & SNN
Secondary NN通知NameNode切换editlog。
Secondary NN从NameNode 获得fsimage和editlog(通过http get方式)。
Secondary NN将fsimage载入内存,然后开始合并editlog。
Secondary NN 将新的fsimage发回给NameNode
NameNode 用新的fsimage替换旧的fsimage