数据清单




前置知识
什么是网络爬虫
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或Web 信息采集器,是一种按
照一定规则,自动抓取或下载网络信息的计算机程序或自动化脚本。
狭义上理解
利用标准的HTTP 协议,根据网络超链接(如https://www.baidu.com/)和Web 文档检索的
方法(如深度优先)遍历万维网信息空间的软件程序。
功能上理解
确定待爬的URL 队列,获取每个URL 对应的网页内容(如HTML/JSON),解析网页内容,并
存储对应的数据。
本质:
网络爬虫实际上是通过模拟浏览器的方式获取服务器数据

网络爬虫的作用
- 可以实现搜索引擎
利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,
在需要检索某些信息的时候,只需在采集回来的信息中进行检索,即实现了私人的搜索引擎。 - 大数据时代,可以让我们获取更多的数据源
- 可以更好地进行搜索引擎优化(SEO)
网络爬虫的分类
通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、
增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。
实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
通用网络爬虫
爬行对象从一些种子URL 扩充到整个Web,主要为门户站点搜索引擎和大型Web 服务提供商采集数据。
通用网络爬虫的爬取范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求较低。
聚焦网络爬虫
又称为主题网络爬虫:是指选择性地爬行那些与预先定义好的主题相关的页面。
一个常见的案例是基于关键字获取符合用户需求的数据。
增量网络爬虫
对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定
程度上保证所爬行的页面是尽可能新的页面,历史已经采集过的页面不重复采集。
常见的案例有:论坛帖子评论数据的采集(如下图所示论坛的帖子,它包含400多页,每次启动
爬虫时,只需爬取最近几天用户所发的帖子);天气数据的采集;新闻数据的采集;股票数据的采集等。
Deep Web 爬虫
指大部分内容不能通过静态链接获取,只有用户提交一些表单信息才能获取的Web 页面。例如,
需要模拟登陆的网络爬虫便属于这类网络爬虫。
另外,还有一些需要用户提交关键词才能获取的内容,如京东淘宝提交关键字、价格区间获取
产品的相关信息。
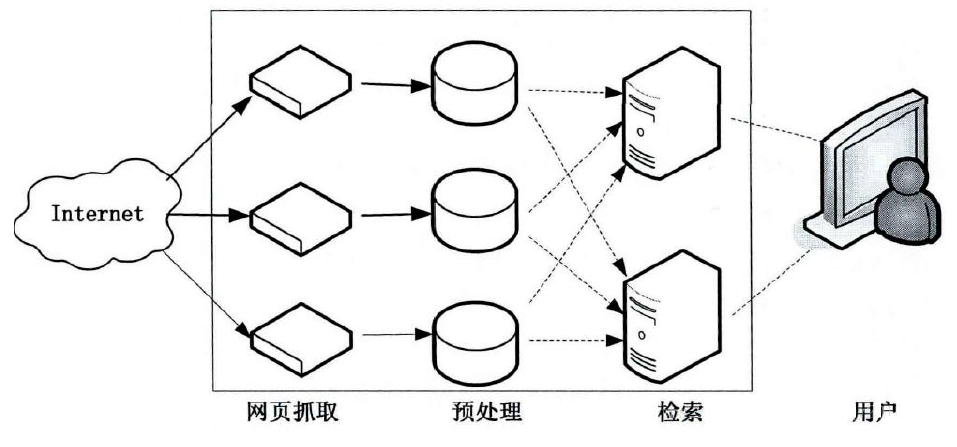
网络爬虫的流程
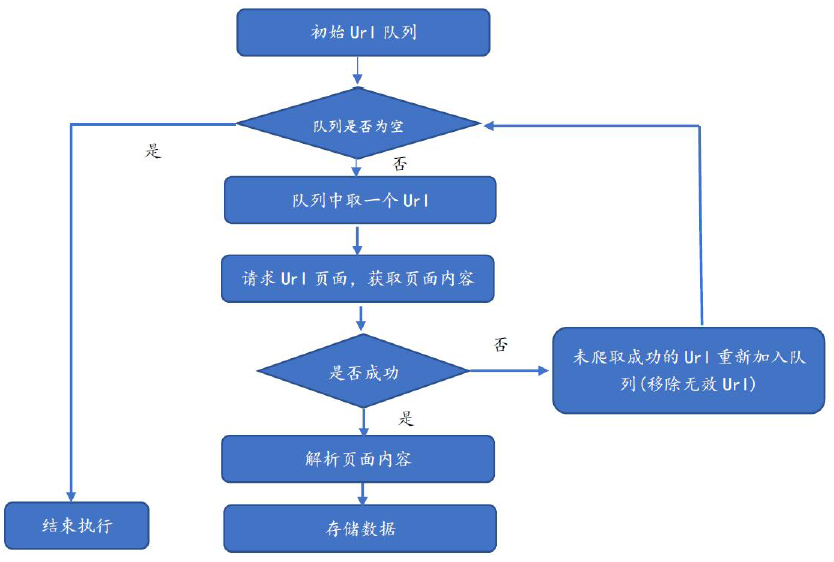
具体流程为:
- 需求者选取一部分种子URL(或初始URL),将其放入待爬取的队列中。如在Java 网络爬虫中,
可以放入LinkedList 或List 中。 - 判断URL 队列是否为空,如果为空则结束程序的执行,否则执行第三步骤。
- 从待爬取的URL 队列中取出待爬的一个URL,获取URL 对应的网页内容。在此步骤需要使用响
应的状态码(如200,403等)判断是否获取数据,如响应成功则执行解析操作;如响应不成功,则
将其重新放入待爬取队列(注意这里需要移除无效URL)。 - 针对已经响应成功后获取到的数据,执行页面解析操作。此步骤根据用户需求获取网页内容里的
部分数据,如汽车论坛帖子的标题、发表的时间等。 - 针对3步骤已解析的数据,将其进行存储。
网络爬虫的爬行策略
一般的网络爬虫的爬行策略分为两种:深度优先搜索(Depth-First Search)策略、广度优先搜
索(Breadth-First Search)策略。
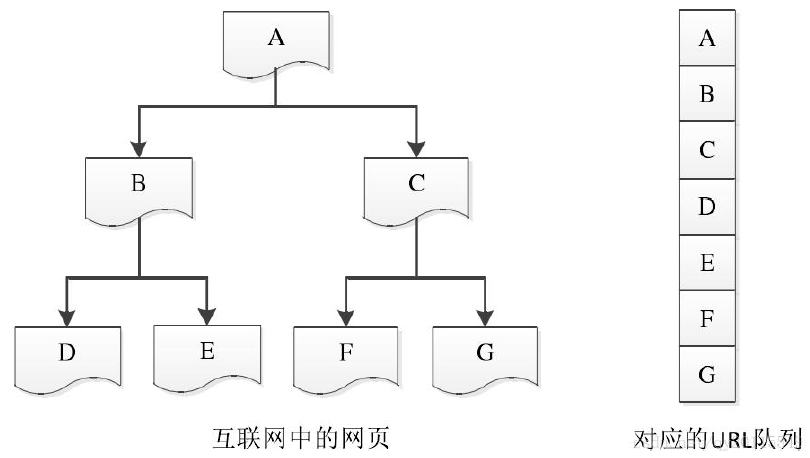
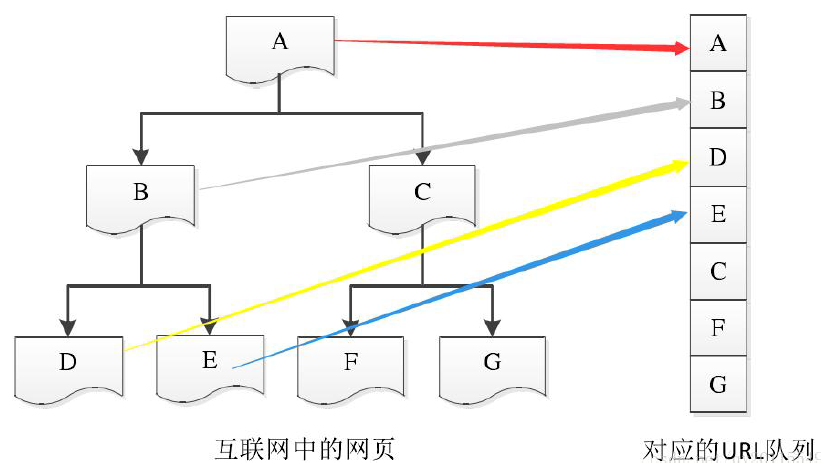
深度优先搜索策略
从根节点的URL 开始,根据优先级向下遍历该根节点对应的子节点。当访问到某一子节点URL
时,以该子节点为入口,继续向下层遍历,直到没有新的子节点可以继续访问为止。接着使用回溯
的方法,找到没有被访问到的节点,以类似的方式进行搜索。下图给出了理解深度优先搜索的一个
简单案例:
广度优先搜索策略
也称为宽度优先,是另外一种非常有效的搜索技术,这种方法按照层进行遍历页面。下图可帮
助理解广度优先搜索的遍历方式