因课题需要,开始捣鼓CNN——卷积神经网络……
以下记录一下从各方各面提取的信息:
190711四:
【西瓜书】:P114
@CNN的采样层亦称为“汇合”层(pooling),其作用是基于局部相关性原理进行亚采样,从而在减少数据量的同时保留有用信息。
@近来人们在使用CNN时常将Sigmoid激活函数替换为修正线性函数
f(X)= 0, if x <0,
x, otherwise
这样的神经元称为 ReLU(Rectified Linear Unit),ReLU(x) = max(0,x)
此外,pooling层的操作常采用“最大”或“平均”。
【SJ's 毕业论文】:
与下类似。
【卷积神经网络CNN完全指南终极版(一): https://zhuanlan.zhihu.com/p/27908027】
【卷积神经网络CNN完全指南终极版(二): https://zhuanlan.zhihu.com/p/28173972】
(1)导论
feature在CNN中也被成为卷积核(filter),一般是3X3,或者5X5的大小。
(2)卷积运算 (卷积层)
对应相乘再累加(要取平均吗?)
根据步长移动计算的窗口,卷积计算的结果是一张完整的feature map。
feature map 是每一个feature从原始图像中提取出来的“特征”。其中的值,越接近为1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
一个feature(卷积核)作用于图片产生一张feature map,对这张X图来说,我们用的是3个feature,因此最终产生3个 feature map。
(3)非线性激活(ReLU层)
在神经网络中用到最多的非线性激活函数是Relu函数,它的公式定义如下:f(x)=max(0,x) 即,保留大于等于0的值,其余所有小于0的数值直接改写为0。
——为什么要这么做呢?
上面说到,卷积后产生的特征图中的值,越靠近1表示与该特征越关联,越靠近-1表示越不关联,而我们进行特征提取时,为了使得数据更少,操作更方便,就直接舍弃掉那些不相关联的数据。
(4)池化层 (pooling层)
——分为Max Pooling 最大池化(用的较多)、Average Pooling平均池化。顾名思义,最大池化就是取最大值,平均池化就是取平均值。
——卷积操作后,我们得到了一张张有着不同值的feature map,尽管数据量比原图少了很多,但还是过于庞大(比较深度学习动不动就几十万张训练图片),因此接下来的池化操作就可以发挥作用了,它最大的目标就是减少数据量。
——拿最大池化举例:选择池化尺寸为2x2,因为选定一个2x2的窗口,在其内(这个窗口内,有4个元素,选出最大的1个)选出最大值更新进新的feature map。
——新的feature map,数据量减少了很多,因为:
最大池化保留了每一个小块内的最大值,所以它相当于保留了这一块最佳匹配结果(因为值越接近1表示匹配越好)。这也就意味着它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了(只留下特征信息,去除了位置信息了。)。这也就能够看出,CNN能够发现图像中是否具有某种特征,而不用在意到底在哪里具有这种特征。这也就能够帮助解决之前提到的计算机逐一像素匹配的死板做法。
(5)全连接层 (Fully connected)
——全连接层,顾名思义就是全部都连接起来。(而卷积层其实是局部连接,局部连接与参数共享是卷积神经网络最重要的两个性质!)
——全连接层要做的,就是对之前的所有操作进行一个总结,给我们一个最终的结果。它最大的目的是对特征图进行维度上的改变,来得到每个分类类别对应的概率值。
——用的是Softmax,它是一个分类函数,输出的是每个对应类别的概率值。
比如:【0.5,0.03,0.89,0.97,0.42,0.15】就表示有6个类别,并且属于第四个类别的概率值0.89最大,因此判定属于第四个类别。
(6)神经网络的训练与优化
——训练的是啥??训练的就是那些卷积核(filter)。
190713六:
偶然邂逅胡晓曼大神的一篇博客:
【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理:https://www.cnblogs.com/charlotte77/p/7759802.html
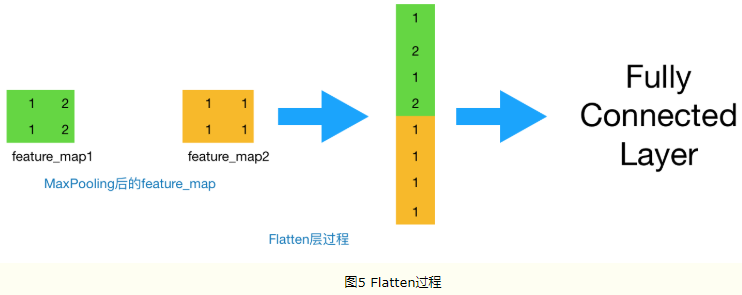
做完Max Pooling后,我们就会把这些数据“拍平”,丢到Flatten层,然后把Flatten层的output放到full connected Layer里,采用softmax对其进行分类。
【关于dropout】
dropout是什么意思: —— https://www.jianshu.com/p/b5e93fa01385
dropout 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络。
【NLP第10课:动手实战基于 CNN 的电影推荐系统: https://www.jianshu.com/p/c4b042c6dfa7】
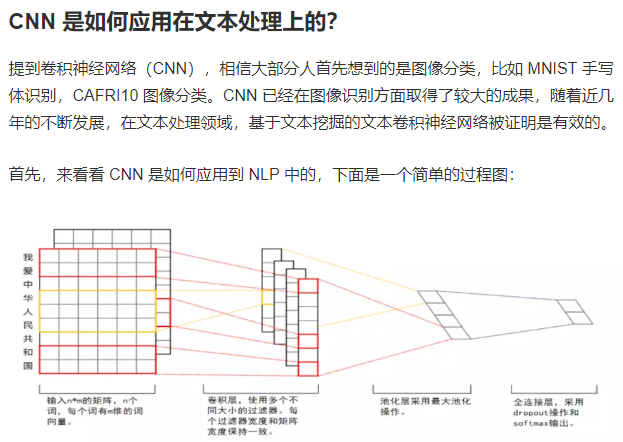
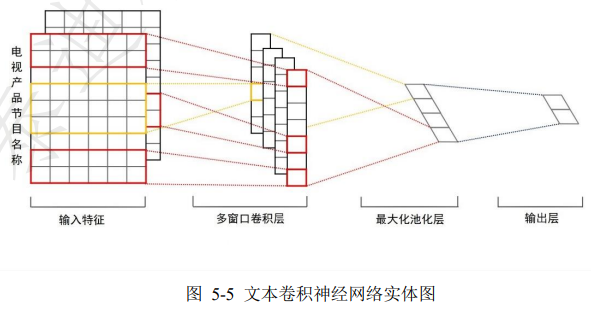
可是,CNN如何用到CF下去 ???
190722一晚
与Dr.PH的交流:
关于CNN,输入是多张图片,比如是猫的图片,但是每张图片中,猫的位置都是不一样的。
多个卷积核,所有卷积核合起来可以构成一只猫的全部特征,如卷积核1为眼睛,卷积核2为耳朵等。
但是这个卷积核啊,是需要训练的。最后全连接层,的softmax之后分类时有个权重也是要训练的参数。