引言:我写本文的宗旨在于给需要使用XML,而又对XML不是很熟悉的人们提供一种使用思路,而不没有给出具体的使用方法,至于下文中提到的使用方法,还未尝试过,都是从网上整理而来!
一、概述
什么是XML?
xm是l可扩展标记语言缩写,xml是互联网数据传输的重要工具,它可以跨越互联网任何的平台,不受编程语言和
操作系统的限制,可以说它是一个拥有互联网最高级别通行证的数据携带者。xml是当前处理结构化文档信息中相当
给力的技术,xml有助于在服务器之间穿梭结构化数据,这使得开发人员更加得心应手的控制数据的存储和传输。
什么是DTO?
DTD的作用是定义XML的合法构建模块,它使用一系列的合法元素来定义文档结构。
什么是XML Schema?
XML Schema是对XML文档结构的定义和描述,其主要的作用是用来约束XML文件,并验证XML文件有效性。
由于XML中可以使用自己定义的元素,由于是自己定义的,当给别人使用的时候,别人怎么知道你的XML文件中写是什么东西呢?
这就需要在XML Scheme文件中声明你自己定义了些什么元素,这些元素都有些什么属性。
Schema与DTO的区别:
(1) Schema本身也是XML文档,DTD定义跟XML没有什么关系,Schema在理解和实际应用有很多的好处。
(2) DTD文档的结构是“平铺型”的,如果定义复杂的XML文档,很难把握各元素之间的嵌套关系;Schema文档结构性强,各元素之间的嵌套关系非常直观。
(3) DTD只能指定元素含有文本,不能定义元素文本的具体类型,如字符型、整型、日期型、自定义类型等。Schema在这方面比DTD强大。
(4) Schema支持元素节点顺序的描述,DTD没有提供无序情况的描述,要定义无序必需穷举排列的所有情况。Schema可以利用xs:all来表示无序的情况。
(5) 对命名空间的支持。DTD无法利用XML的命名空间,Schema很好满足命名空间。并且,Schema还提供了include和import两种引用命名空间的方法。
SAX解析:
SAX,全称Simple API for XML,是一种以事件驱动的XMl API,是XML解析的一种新的替代方法,解析XML常用的还有DOM解析,PULL解析(Android特有),SAX与DOM不同的是它边扫描边解析,自顶向下依次解析,由于边扫描边解析,所以它解析XML具有速度快,占用内存少的优点,对于Android等CPU资源宝贵的移动平台来说是一个巨大的优势。
Java JDK自带的解析(SAXParserFactory SAXPaeser DefaultHandler)
特点: 一行一行的往下面执行解析的
二、使用步骤及案例
1. SAX解析步骤
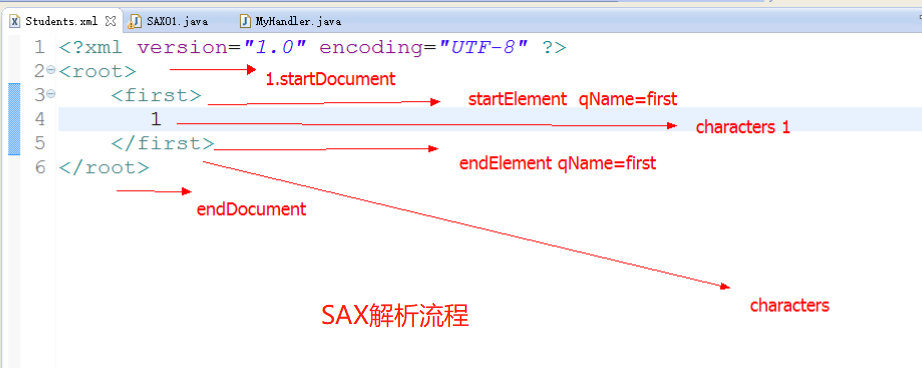
解析步骤: 1.创建一个SAXParserFactory对象 SAXParserFactory factory=SAXParserFactory.newInstance(); 2.获得解析器 SAXParser parser=factory.newSAXParser(); 3.调用解析方法解析xml,这里的第一个参数可以传递文件、流、字符串、需要注意第二个参数(new DefaultHander) File file=new File("girls.xml"); parser.parse(file,new DefaultHandler()); /**注解:--->这里的DefaultHandler表示 DefaultHandler类是SAX2事件处理程序的默认基类。它继承了EntityResolver、DTDHandler、 ContentHandler和ErrorHandler这四个接口。包含这四个接口的所有方法,所以我们在编写事件处理程序时, 可以不用直接实现这四个接口,而继承该类,然后重写我们需要的方法,所以在这之前我们先定义一个用于实现解析 方法如下:*/ 4.创建一个MyHandler类来继承DefaultHandler并重写方法 //定一个名为MyHandler类用来继承DefaultHandler (1)MyHandler extends DefaultHander (2)重写方法,快速记住方法(2个开始,2个结束,1一个文字(charactor--里面的内容)) (3)2个开始:StartDocment(文档的开始)StartElement(元素的开始) 2个结束:endElement(元素的结束) endDocment(文档的结束,标志着xml文件的结束) 1个文字内容:charactor(文字内容) 5.创建一个集合把所解析的内容添加到集合 //分析:目的我们只是需要把xml里面的文字内容添加到我们的集合而不需要其他元素,所以我们需要进行判断得到 //(接上)我们需要的内容(下面会赋一个图帮助理解) 6.接步骤三 输出集合System.out.pritnln(list); 解析完成!
解析流程图:
(1) 待解析的xml
<?xml version="1.0" encoding="utf-8" ?> <girls> <girl id="1"> <name>黄梦莹</name> <age>32</age> </girl> <girl id="2"> <name>刘亦菲</name> <age>33</age> </girl> </girls>
(2) 用于封装数据的实体
/** * 封装实体 * * @author zls * @date 2020/3/19 */ @Data public class Girl { private String id; private String name; private String age; }
(3) 自定义解析xml的类


package sax; import lombok.Data; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; import java.lang.reflect.Field; import java.util.ArrayList; import java.util.List; import java.util.Objects; /** * 自定义xml文件解析的实现类 * 原理:sax是一行一行的往下面执行解析的 * * 参考:https://blog.csdn.net/lsh364797468/article/details/51325540 * @author zls * @date 2020/3/19 */ @Data public class MyHandler extends DefaultHandler { // 准备一个用于添加xml数据的集合、调用Girl类、准一个用于用来保存开始的标签的tag private List<Girl> girls; private Girl girl; private String tag; // 记录xml中元素表中,因为是一行一行的解析的,所以需要记录 /** * 文档的开始 * @throws SAXException */ @Override public void startDocument() throws SAXException { super.startDocument(); // 因为这个方法只调用一次,所以在开始的时候就可以实例化集合 girls = new ArrayList<>(); } /** * 文档结束 * @throws SAXException */ @Override public void endDocument() throws SAXException { super.endDocument(); } /** * 元素的开始 * @param uri * @param localName * @param qName 每次遍历取得的标签,每次只取一行 * @param attributes * @throws SAXException */ @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { super.startElement(uri, localName, qName, attributes); // 这个方法,只有当开始一个元素的时候才会调用, // 通过分析,当外部开始元素为girl的时候,需要将girl实例化 // 将tag赋值 tag = qName; if ("girl".equals(qName)) { girl = new Girl(); } } /** * 元素的结束 * @param uri * @param localName * @param qName * @throws SAXException */ @Override public void endElement(String uri, String localName, String qName) throws SAXException { super.endElement(uri, localName, qName); // 这句话,必须写,因为,当sax解析完一个元素的时候,会自动认为换行符是一个字符,会继续执行 character 方法 。如果不写,就会造成没有数据的现象。 tag = ""; // 这个方法,当到了元素结尾的时候,会调用,应该在这里,将对象添加到集合里面去。 if ("girl".equals(qName)) { girls.add(girl); } } /** * 文字内容 * @param ch * @param start * @param length * @throws SAXException */ @Override public void characters(char[] ch, int start, int length) throws SAXException { super.characters(ch, start, length); // 这里是内容,但是,无法直接判断属于哪一个元素。 String string = new String(ch, start, length); //这两种情况,表示 当前语句执行在 girls 标签内。 if ("name".equals(tag)) {//判断当前内容,属于哪一个元素。 girl.setName(string); } else if ("age".equals(tag)) { girl.setAge(string); } // try { // setFiledValue(tag, string); // } catch (IllegalAccessException e) { // e.printStackTrace(); // } } /** * 使用反射的方式设置字段的值 * * (1) 字段很多的情况 * 问题: * 如果xml中的标签很多,即:类中的属性很多,那么采用以上的方式,难道要写十万个if吗? * 所以这里采用反射的方式,自动的给对象的属性设置上值(学了那么多年的反射终于有了用武之地了)。 * * (2) 类中的属性和xml中的标签有点不一样的情况 * 问题:我遇到的情况是第三方提供的xml里面所有标签都是大写字母,而我们项目字段采用的驼峰命名法,那么如果直接把xml中的标签 * 定义为属性名,那多难看啊,几个单词连在一起都是大写,除了开发的人员自己能看懂以外,以后维护的人员看到了肯定会问候你祖上十八代的。 * 解决:为此,我采用了驼峰命名的方式给实体属性命名,反射的时候可以转换为大写字母和xml中的标签比较 * * (3) 除了用代理的方式,还可以用json转对象的方式 * 我们可以手动的拼接成一个json字符串,然后再采用json转对象的方式也是可以的。这种方式理论上也是可以的,有兴趣可以自己实现以下。 * @param tag * @param value */ public void setFiledValue(String tag, String value) throws IllegalAccessException { if (girl == null) { return; } Field[] declaredFields = girl.getClass().getDeclaredFields(); for (Field declaredField : declaredFields) { if (Objects.equals(declaredField.getName(), tag)) { // 修改字段访问控制权限(字段是私有的,则需要设为可以访问) if(!declaredField.isAccessible()){ declaredField.setAccessible(true); } // 字段类型 String fieldType = declaredField.getType().getSimpleName(); System.out.println("字段:"+ declaredField.getName()+", 字段类型为: " + fieldType); declaredField.set(girl, value); } } } }
(4) 测试类
/** * @author zls * @date 2020/3/19 */ public class SaxPareTest { // 获取test下的resource路径,在测试文件夹下测试时,非类文件必须放在resource及其子文件夹下,要不然编译之后文件就没了 private static String path = SaxPareTest.class.getClass().getResource("/").getPath(); public static void main(String[] args) { // 1.创建对象 SAXParserFactory newInstance = SAXParserFactory.newInstance(); try { // 2.获取解析器 SAXParser saxParser = newInstance.newSAXParser(); // 3.调用方法开始解析xml // 这里的路径到时候根据自己的需要去拼,只要能找到文件即可 String absolutePath = path + "girls.xml"; File file = new File(absolutePath); MyHandler dh = new MyHandler(); saxParser.parse(file, dh); List<Girl> girls = dh.getGirls(); // 4.输出集合 System.out.println(girls); // [Girl(id=null, name=黄梦莹, age=32), Girl(id=null, name=刘亦菲, age=33)] } catch (ParserConfigurationException | SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }
2. 解析XML文件(XML的解析使用 - 消费者)
在比较大的项目中,我们有时会用到服务这个概念,一些服务会以xml的形式返回结果,这个时候就要对XML进行解析,
但很多时候,我们对服务提供的XML结构不甚了解,就算了解了,如果服务被修改XML结构被改变,这个时候以前写好
的解析XML的方法就会出现紊乱,如何解决这个问题呢?其实标准的服务在提供给用户XML的时候会提供给用户对应的
XML描述文件,这就是XSD文件,对此文件进行解析后再利用解析后的XSD文件对XML进行解析,这样即使服务节点变了,
后台的代码也能正确解析当前服务返回的XML文件。
使用方法,参考(案例1):
https://luo-yifan.iteye.com/blog/2036072
我们在使用XSD文件的时候,可以通过cmd命令的形式,将XSD文件生成java文件,生成方法参考:
另外附上一篇写的比较好的xml文件解析的基础教程,参考:
案例2:解析XML文件中的数据,然后将解析后的数据保存到数据库
参考:
2. 生成XML文件(生产者)
案例1:java制作xml文件
参考:java生成XML文件
案例2:根据xsd定义的xml格式封装数据并生成xml文件
参考:https://zmft1984.iteye.com/blog/798384
背景:
在项目组最近一次的版本开发中,有个需求是将我们项目数据库中的基础数据生成到xml文件中,并通知第三方获取这个xml文件。
刚开始是想将数据按照xml的格式拼接成字符串,并逐行的写到文件中,但是总觉得这样做和java的面向对象格格不入。于是baidu了一
下,果然有比拼接字符串更好的办法,具体实现步骤如下:
(1) 将要生成的xml文件的格式编写到xsd文件中,如我们项目中用到的Channel.xsd;
(2) 借助于jdk的xjc命令,将xml中的节点转换成java对象类以供数据封装,具体实现是编写一个bat文件,直接执行bat文件即可;
(3) 准备数据封装,将从数据库中查询出来的数据按照xml格式从底层节点开始,逐层向上封装;
(4) 使用jdk的JAXBContext将封装好的数据输出到xml文件。
案例3:根据xsd定义的xml格式封装数据并生成xml文件
背景概述:
由于很多厂家在开发同一套系统,而我们公司只是参与了系统中的一部分,因此别的公司要求我们公司
将系统中某几个模块功能的数据封装成为一个xml文件(当系统中这几个模块点击添加,然后是填写各种数据,
最后保存表单提交时需要生产一个xml文件),然后上传到ftp服务器,其他公司给我们提供了一个XSD文件,
里面描述了对生产XML文件的要求,同时也还提供了一个word文档说明哪个元素里面放什么内容。
开发步骤:
其实,这个需求就相当于案例2中的一样,说白了就是要我们根据xsd定义的xml格式封装数据,并生产xml文件。
但是感觉使用案例2中的方式太过去麻烦,于是就想有没没有什么简单的方式呢?于是:
由于公司使用的是springboot框架,里面有一个东西叫thymeleaf,而我们可以自己定义模板,于是我们基于模板去生成
xml文件。
具体步骤:
(1) 更具提供的xsd文档,自己制作一个html模板,并将自己制作的这个模板和springboot集成;
(2) 将自己系统中的业务数据传递给这个模板,然后通过thymeleaf中的表达式写到这个html模板上(类似于我们平时渲染html页面一样);
(3) 将渲染完的这个模板后缀修改为.xml,然后通过ftp上传到别的公司要求的目标地址上。
具体代码的话后期在提供:
代码业务方法:
/** * 测试类 */ public class Test{ @Autowired private IUserService userService; @Test public void test(){ //这里对应的是user模板.html页面 ModelAndView view = new ModelAndView("user模板"); view.addObject("username", "gaigai"); view.addObject("age", 23); userService.upload(view,"user自动发布文件.xml"); } }
UserServiceImpl中的给springboot添加模板的方法:
springboot中模板引擎的使用,可以参考:thymeleaf模板引擎入门(当然,这个参考文档没有用springboot,
如果用springboot的话,集成起来应该更方便!)
public void upload(ModelAndView view, String filename) { FtpClient ftpClient = null; try { //Context用于保存模板中需要的一些变量。例如要把变量传递到模板中, //就可以先把变量放入IContext的实现类中,然后在模板中获取该变量的值。 Context context = new Context(Locale.CHINESE,view.getModel()); //process方法用于解析模板并利用当前response对象的writer把模板输出到浏览器。 String template = templateEngine.process(view.getViewName(), context); //通过ftp服务器上传到指定的目录 ByteArrayInputStream bais = new ByteArrayInputStream(template.getBytes("UTF-8")); ftpClient = ftpSource.borrowObject(); ftpClient.putFile(filename,bais); } catch (Exception e) { //"获取ftp连接异常! } finally { if(ftpClient != null){ ftpSource.returnObject(ftpClient); //org.apache.commons.pool2 jar包 } } }
user模板.html 页面为:
<?xml version="1.0" encoding="UTF-8" ?> <user xmlns:th="http://www.thymeleaf.org"> <username th:text="${username}">花千骨</username> <age th:text="${age}">32</age> </user>
我这里最终生成的 user自动发布文件.xml 和这里的html页面内容一致,只不过是里面的数据被替换了。
参考: