---
title: 不懂SQL优化?那你就OUT了(六)
MySQL如何优化--ORDER BY
date: 2018-12-08
categories: 数据库优化
---

在日常开发中,我们经常会使用 order by 子句对某些数据进行排序处理,那么在mysql中使用order by子句时,我们应该怎样优化order by 子句后的查询字段来提高查询效率和排序速度。
在mysql中使用 order by 进行排序有两种方式:
1. 扫描有序索引进行排序(推荐)
2. 使用文件进行排序(using filesort:内存/磁盘文件排序获取结果 )
在InnoDB存储引擎以B+树作为索引的底层实现,B+树的叶子节点存储着所有数据页而内部节点不存放数据信息,并且所有叶子节点形成一个(双向)链表。
你可以简单的理解为:索引是一种特殊的文件,当我们建立索引时,mysql会使用双向链表的方式来事先给数据进行排序。
例如:
CREATE TABLE t_testOrderBy(
userid INT PRIMARY KEY AUTO_INCREMENT, -- 用户编号
username VARCHAR(25), -- 用户姓名
userAge INT, -- 用户年龄
usergender CHAR(3), -- 用户性别
provice VARCHAR(25), -- 所在省份
city VARCHAR(25), -- 所在城市
address VARCHAR(200) -- 详细地址
);
测试数据:
INSERT INTO t_testOrderBy VALUES(NULL,'张三',18,'男','四川省','成都市','xxxx路222号');
INSERT INTO t_testOrderBy VALUES(NULL,'李四',20,'女','云南省','昆明市','xxx北路12号');
INSERT INTO t_testOrderBy VALUES(NULL,'王五',24,'男','贵州省','遵义市','xxxxx路18号');
INSERT INTO t_testOrderBy VALUES(NULL,'赵六',19,'女','四川省','绵阳市','xx路234号');
INSERT INTO t_testOrderBy VALUES(NULL,'孙琦',28,'男','云南省','玉溪市','xxxx路324号');
INSERT INTO t_testOrderBy VALUES(NULL,'王晓琪',21,'女','云南省','玉溪市','xxxx路123号');
例如:
图1:
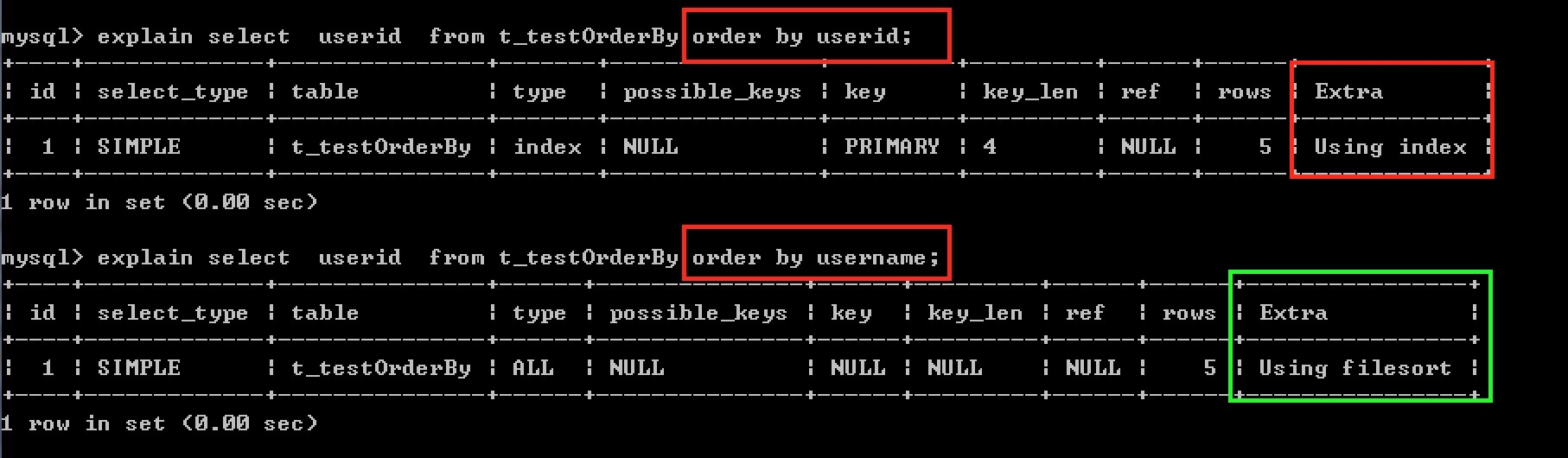
从图1可以看出:
使用userid进行排序时,userid上有主键索引,mysql会直接遍历userid索引的叶子节点链表,不需要进行额外的排序操作,这就是用索引扫描来排序。
使用 username 字段上没有任何索引,此时B+树结构不存在,mysql就只能先扫表筛选出符合条件的数据,再将筛选结果根据username排序。这个排序过程就是filesort。
### 使用有序索引排序时
sql语句中,where子句和order by 子句都可以使用索引, where子句使用索引避免全表扫描,order by 子句使用索引尽量避开使用文件排序(filesort),以提高查询效率。
虽然索引能提高查询效率,但在一条sql里,对于一张表的查询 一次只能使用一个索引(注:排除发生index merge的可能性),也就是说当where子句与order by 子句使用的索引不一致时,MySQL只能使用其中一个索引(B+树)。
####order by 可以使用索引
1. 当select的字段包含在索引中时,能利用到索引排序功能,进行覆盖索引扫描.
例如: 为表中的username添加索引。



可以看出当 select 字段中包含了 userage(未建立索引)时,则不能使用索引。
2.当有联合索引时,order by 子句使用索引必须遵循索引的最左前缀原则。
例如: 为 省份,城市,详细地址建立联合索引

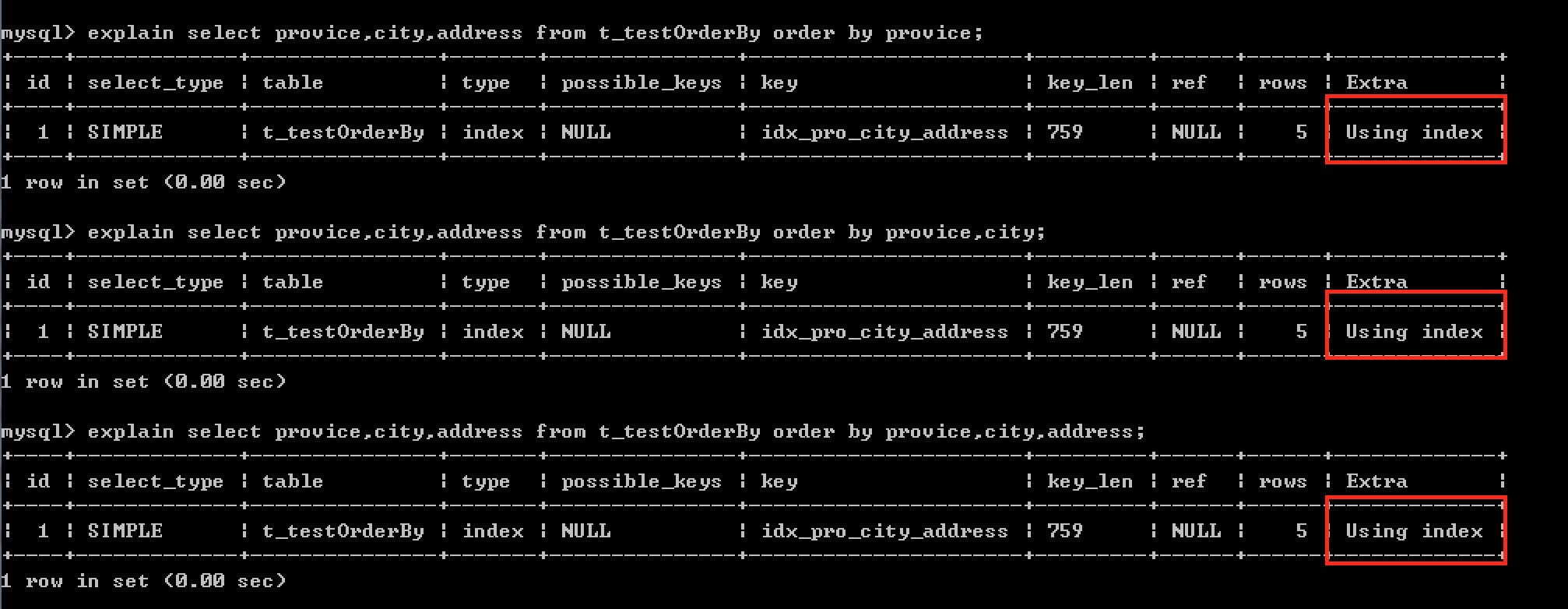
当不遵循最左前缀原则时,则会使用filesort

3.联合索引中的一部分做等值查询 ,另一部分作为排序字段。(当然还是要遵循最左前缀原则)
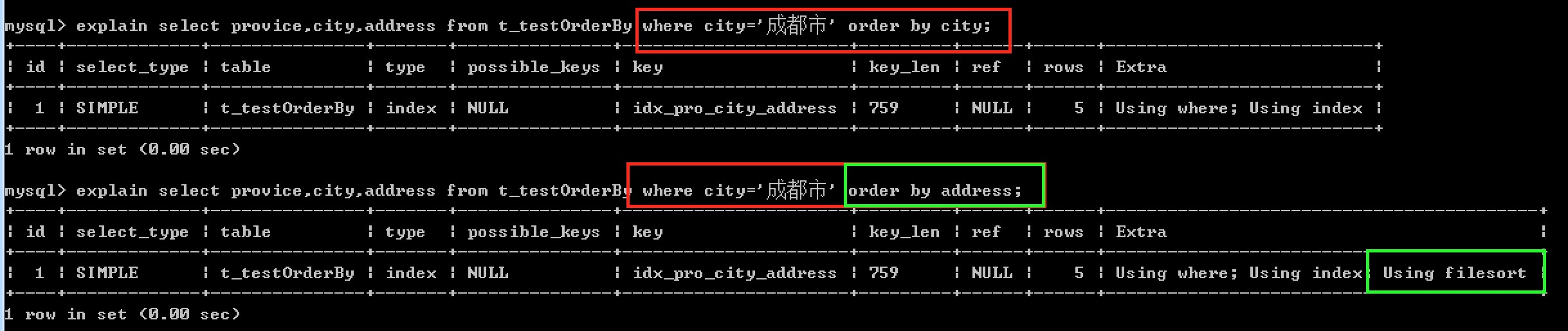
####order by 不使用索引排序
1.select字段在多个索引中,无法使用索引排序。

从上图中可以看出,username的一个独立的所以,二而provice是联合索引,当select字段中有多个索引列时,无法使用索引排序
2.对不同的关键字使用ORDER BY:

3.当有联合索引时,order by 子句使用索引 不 遵循索引的最左前缀原则,无法使用索引排序

4. 升降序不一致,无法使用索引排序。

5.order by 的字段使用函数
6.返回数据量过大也会不使用索引。
## 使用文件进行排序(后面在介绍)
对于不能利用索引避免排序的sql,数据库不得不自己实现排序功能以满足用户需求,此时sql的执行计划中会出现“Using filesort”,这里需要注意的是filesort并不意味着就是文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size参数与结果集大小确定。
如果排序不可避免,可以用下面的办法加速:
1. 避免使用 “select * ” 。
2. 增加sort_buffer_size变量的大小。
3. 增加read_rnd_buffer_size变量的大小。
4. 更改tmpdir指向具有大量空闲空间的专用文件系统。
5. 使用合适的列大小存储具体的内容,比如对于city字段 varchar(25)比varchar(200)能获取更好的性能.
##order by 总结
